The post walks through the barriers, where the opportunities are, and gives a concrete checklist to make your own work more actionable.
The Problem

There are hundreds of interpretability papers published every year. Probing, circuits, sparse autoencoders, feature attribution — the field is thriving. This growth is driven by the intuition that if we understand how models work, we should be able to make them safer, more reliable, and better aligned with what we actually want.
But here's the uncomfortable truth: most of this work hasn't translated into things used outside of interpretability research itself. Insights rarely inform changes to models, training procedures, deployment decisions, or policy. Papers get published, methods get cited—but predominantly in a conceptual way. Most citations don't credit interpretability work for changes to training, architecture, or evaluation.
This has motivated growing calls to focus on clearly demonstrable outcomes beyond "understanding" itself. We argue that what is missing is not methods, but evaluation criteria: a shared framework for determining when interpretability research is successful from a practical, decision-oriented perspective.
Defining Actionable Interpretability
We define an interpretability-oriented work as actionable if it produces insights about an AI model that inform or guide actions toward non-interpretability objectives. In plain terms: your work is actionable if someone can take what you found and do something useful with it—improve a model, make a deployment decision, inform a policy, or help a domain expert.
Actionability isn't binary. We characterize it along two key dimensions:
Two Dimensions of Actionability
📐 Concreteness
How specific is the proposed action?
“could inform safety research” → exact implementation with code
✅ Validation
Has anyone actually tested it?
“this might help” → quantitative evidence it actually does
Most existing work clusters in the low-concreteness, low-validation region—providing directional insights that motivate future work, but without articulating or testing specific actions. The field needs more work at the high end of both axes: precise, validated actions informed by interpretability. In the paper, we map existing work onto this space to show where current contributions land and what the gaps look like.
💡 What high actionability looks like in practice
- The discovery of induction heads in Transformers
Olsson, C. et al. (2022). In-context Learning and Induction Heads. Transformer Circuits Thread. directly influenced the selective state-space design of Mamba.Gu, A. & Dao, T. (2024). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. - ReFT was directly inspired by interpretability findings about how models represent concepts.
Wu, Z. et al. (2024). ReFT: Representation Finetuning for Language Models. NeurIPS 2024. - Anthropic used internal activation analysis to audit Claude's safety behaviors.
Anthropic (2025). System Card: Claude Sonnet 4.5. Technical Report. - Concept vectors extracted from AlphaZero surfaced novel chess strategies that human grandmasters could learn from.
Schut, L. et al. (2025). Bridging the Human–AI Knowledge Gap Through Concept Discovery and Transfer in AlphaZero. PNAS. - Geva et al.'s key-value memory view of transformer feed-forward layers
Geva, M., Schuster, R., Berant, J. & Levy, O. (2021). Transformer Feed-Forward Layers Are Key-Value Memories. EMNLP 2021. has directly shaped architecture design at frontier labs.Cheng, X., Zeng, W., Dai, D. et al. (2026). Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models. Sadhukhan, R., Cao, S., Dong, H. et al. (2026). STEM: Scaling Transformers with Embedding Modules.
For more examples, see the posters from the ICML 2025 workshop.
Why Isn't Interpretability Actionable Yet?
Several barriers reinforce a cycle where actionability isn't prioritized, methods lack validation, and deployment yields little feedback. We discuss these in detail in Section 3 of the paper; here's a summary.
Five Domains Where Interpretability Has Real Leverage
Where should the field focus? We identify five domains where interpretability provides a fundamental advantage—where answering why questions about models unlocks improvements that other approaches cannot.
We further discuss these opportunities in Section 4 of the paper
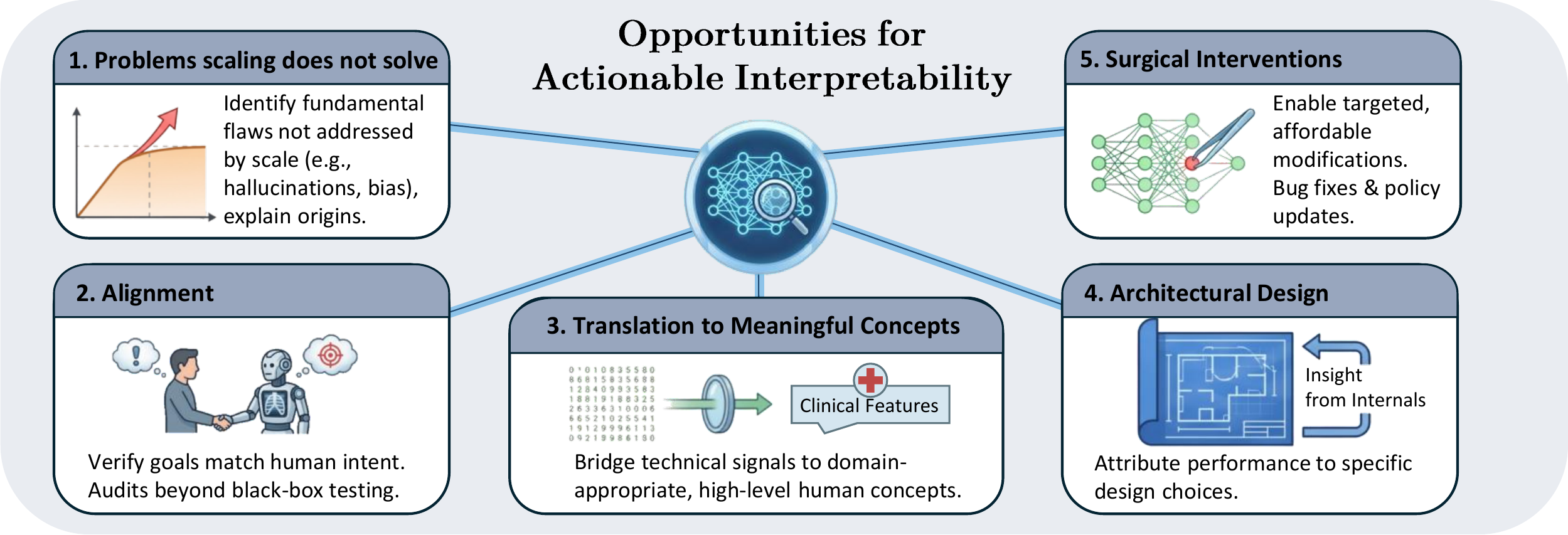
Problems Scaling Won't Fix
Certain failure modes persist or even worsen with model and data scale, including hallucinations, catastrophic forgetting, biases, and adversarial brittleness. The persistence of these failures across model scales suggests they are fundamental to our current modeling paradigm rather than due to limited capacity. Interpretability offers a path forward precisely because it can identify why models fail.
Alignment
As AI systems become more capable, ensuring they behave as intended becomes more critical and more difficult. Alignment today still relies on fine-tuning and data curation rather than understanding-driven interventions, but as AI progresses, verifying that AI goals match human goals will shift from aspiration to necessity.
Surgical Interventions
Retraining a flawed model is expensive and risks introducing other unexpected outcomes. Interpretability enables targeted modifications; identifying components responsible for unwanted behaviors allows surgical fixes while preserving other functionality.
Architecture Design
Current improvements emerge largely through trial and error—an inefficient, opaque process where success may not scale or transfer to new domains. Interpretability could accelerate progress by narrowing the space of plausible architecture modifications, reducing both labor and compute required.
Meaningful Explanations
The most natural role of interpretability is explaining model behavior, yet translating internal signals into meaningful concepts remains a critical bottleneck. In high-stakes domains like healthcare, a radiologist needs to know if an AI-assisted diagnosis depends on clinically relevant features, not which pixels activate; automated methods that translate technical explanations into domain-appropriate, actionable concepts could unlock interpretability's core promise.
Who Takes the “Action” in “Actionable”?
Different stakeholders have different capabilities and motivation. An interpretability work becomes more actionable if it is explicit about its intended audience and the decisions it aims to support.
| Audience | Example Action | What They Need |
|---|---|---|
| AI Developers | Curate data, edit model behavior | Data-point analysis, modification methods |
| Deployment Engineers | Debug application failures | Explanations for model errors |
| Domain Experts | Validate reasoning, refine workflows | Explanations tied to domain features |
| End Users | Trust or override model output | High-level rationale in human terms |
| Policymakers | Enforce compliance and transparency | System-level summaries |
These actors rarely operate in isolation. A clinician's feedback about unreliable explanations may reveal failure modes to engineers. A policymaker's compliance requirements may drive developers toward specific mitigations.
What Actions Does Interpretability Enable?
We classify actions by what they affect. Click each category to explore the specific actions interpretability unlocks.
Decisions that directly change model behavior—modifications to training data, inputs, weights, or internal computations. Primarily made by developers and researchers with access to model internals.
Interpretability can identify which training examples help and which hurt.
- Influence Functions trace model performance back to individual training examples, enabling targeted data selection. Removing detrimental robot demonstrations achieved state-of-the-art results with only 33% of the original data.
Interpretability can identify components responsible for specific behaviors, enabling targeted interventions.
- Model Editing — Modifies weights to correct behaviors without full retraining.
Meng, K. et al. (2022). Locating and Editing Factual Associations in GPT. NeurIPS 2022. - Runtime Interventions — Steer activations along interpretable directions at inference time.
Li, K. et al. (2023). Inference-Time Intervention: Eliciting Truthful Answers from a Language Model. NeurIPS 2023. Turner, A.M. et al. (2023). Steering Language Models with Activation Engineering.
These are just two examples — we cover additional actions including model input selection, training decisions, safety interventions, and more in Section 5 of the paper.
These change what humans do with model predictions—when to trust them, when to override them, and how to integrate them into workflows. Actions here are taken by end users, domain experts, and deployment engineers.
Interpretability helps users understand when to trust and when to override model outputs.
- Neuro-Symbolic Systems — Combining LLMs with rule-based expert systems provides the transparency radiologists need to confidently use AI while maintaining oversight.
Prenosil, G.A. et al. (2025). Neuro-Symbolic AI for Auditable Cognitive Information Extraction from Medical Reports. Communications Medicine. - Uncertainty Estimation — Internal representations enable users to detect potential errors and decide when to trust model outputs.
Kadavath, S. et al. (2022). Language Models (Mostly) Know What They Know.
Internal mechanisms support routing decisions—whether to return a model's answer or escalate to alternatives.
- OOD Detection — Internal causal mechanisms can identify out-of-distribution failures.
Huang, J. et al. (2025). Internal Causal Mechanisms Robustly Predict Language Model Out-of-Distribution Behaviors. - Error Prediction — Interpretability methods can predict errors on unseen distributions, informing deployment boundaries.
Li, V.R. et al. (2025). Can Interpretation Predict Behavior on Unseen Data?
More examples — including uncertainty-based routing and backdoor detection — in Section 5 of the paper.
Beyond immediate interventions, interpretability informs how the field builds and governs future systems. This has longer-term, broader impact across policy, science, and architecture.
When models exceed human expertise, interpretability becomes a mechanism for transferring knowledge from AI back to humans.
- Concept Vectors — Vectors extracted from AlphaZero surfaced novel chess strategies that human grandmasters could learn from.
Schut, L. et al. (2025). Bridging the Human–AI Knowledge Gap Through Concept Discovery and Transfer in AlphaZero. PNAS.
Interpretability can shift architecture design from trial-and-error toward principled engineering.
- Induction Heads — The discovery of induction heads in Transformers
Olsson, C. et al. (2022). In-Context Learning and Induction Heads. Transformer Circuits Thread. provided a mechanism for in-context learning that traditional state-space models lacked, directly influencing the selective state-space design of the Mamba architecture.Gu, A. & Dao, T. (2024). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. COLM 2024.
We also discuss policy and regulation implications — including the EU AI Act and GDPR — in Section 5 of the paper.
How to Evaluate Actionability
Now to a core part of creating actionable interpretability work: being able to evaluate whether it's actually actionable. Current practice often evaluates interpretability methods against each other—"grading on a curve." This is insufficient. We need metrics that measure whether insights actually enable better decisions and outcomes. Here are the criteria we propose — we discuss each in detail, including how to measure them in practice, in Section 6 of the paper:
Comparative Utility
Does the interpretability-based method outperform standard baselines like prompting or fine-tuning? Actionability means marginal leverage over simpler methods.
Mechanistic Faithfulness
Does intervening on identified components produce predicted changes—altering target behavior while leaving unrelated behavior intact?
Generalization
Does the insight hold across seeds, perturbations, architectures, and scales without requiring rediscovery?
Specificity
When you intervene on an identified component, does it affect only the targeted behavior—or does it also disrupt other capabilities? Broad side effects signal that the finding is entangled, not specific.
Task Enhancement
The most direct user-facing test: do explanations improve how humans perform the task the model supports — their accuracy, speed, or ability to know when to trust or override the model? This typically requires human-subject evaluations, and prior work suggests the bar is harder to clear than it sounds.
Understandability
Can the target audience actually understand the explanation? A technically faithful explanation is useless if a clinician or policymaker can't make sense of it. Understandability is orthogonal to correctness — an explanation can accurately reflect model behavior and still be completely unusable.
Reliability
Are explanations stable across random seeds and minor perturbations? Even explanations that are faithful and understandable become useless if they fluctuate unpredictably.
Governance Utility
In a policy context, interpretability isn't a scientific diagnostic — it's an institutional lever. Does the method enable practical governance actions: safety audits, compliance verification, or detecting dangerous mechanisms? Does it reduce monitoring costs compared to blunt instruments like pausing deployment? Can regulators and safety teams actually use it?
What We're Not Saying
We are not arguing that all interpretability work must immediately yield actionable outcomes, or that purely exploratory work lacks value. Curiosity-driven research is vital—we don't yet know which techniques will ultimately prove useful.
What we are saying is that tracking actionability as a yardstick will strengthen the field's impact, hold methods to higher standards, and provide evidence that findings reflect genuine model behavior rather than analysis artifacts. Methodological novelty and application demonstration are not at odds—grounding findings in real-world actions provides stronger evidence that the interpretability insights are real.
The burden now falls on the research community: to reward actionable contributions alongside explanatory depth, to establish evaluation criteria that track the utility of interpretability insights, and to build infrastructure that connects understanding to impact.
The Actionability Checklist
If you're working on interpretability, ask yourself these questions:
📋 Actionability Checklist for Interpretability Research
Click on each step to learn more.
- Surpasses standard baselines (prompting, fine-tuning)
- Generalizes across setting variations and seeds
- Produces targeted effects without degrading other capabilities
- Yields useful explanations for the target audience